科普 | 区块链协议中的随机性

分享到朋友或朋友圈

我们今天发表的一篇短论文介绍了 NEAR 协议所采用的随机信标。佐餐食用的本博文将着重讨论随机性的重要意义、实现难度以及其它协议的实现路径。
包括 NEAR 在内的诸多新型区块链协议都高度依赖于随机性,以抉择由哪些成员执行协议中的特定操作。如果恶意攻击者能影响随机源,他们就有机会增加自己被选中的概率,最终威胁协议的安全性。
分布式随机性同样也是众多区块链应用的重要基石。举例来说,假如某个智能合约接受用户的赌约,规则为无偏倚地产生一个随机数,据此以 49% 的概率返还两倍押注,51% 的概率没收赌资。如果恶意攻击者可以影响或者预测该随机数,他们就能旱涝保收,并很快搬完合约中所有的资金。
在设计分布式随机性算法时,我们希望它具备以下属性:
算法必须公正无偏(unbiasable)。换言之,不允许有任何参与者能丝毫影响随机数生成器的结果。
算法无法被预测。即在随机数生成之前,所有的参与者都不知道会生成什么样的结果(也不能预测到其属性)。
协议需要具备在某些节点掉线时仍保持正常运行的容错能力,即使有节点故意阻碍协议,也可以继续运行。
本文将介绍分布式随机信标的基础知识,说明为何朴素的技术方案无法达成效果。在最后,我们将介绍 DFinity 、Ethereum Serenity 以及 NEAR 协议所采用的随机信标方案,并逐一剖析其优越性与不足之处。
RANDAO
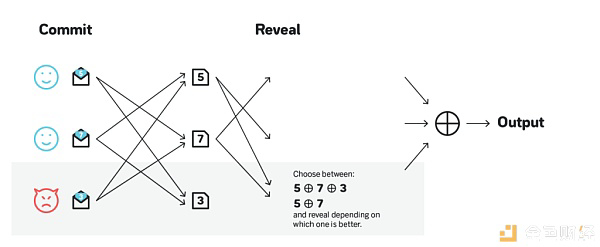
RANDAO 非常简单,因此也是一个十分常见的随机性实现方案。其大致思想是网络中的所有人首先各自私下选定某个随机数,然后向 RANDAO 提交该随机数的承诺,接着所有人根据一定的共识算法从所有的承诺中选定一组;在参与者揭示这组承诺背后的随机数之后,大家对该组随机数达成共识;最后这组随机数进行异或操作得到的结果就是一轮 RANDO 协议产生的随机数。
RANDO 的做法的确让随机数难以预测,并且随机数享有与底层共识协议一样的活性,但仍有可以钻空子的地方。比方说,恶意攻击者看到网络中所有其他人揭露各自所选取的随机数之后,可以根据自身随机数先执行异或运算,并根据结果对自己的利弊来决定是否要揭露自己的随机数。这种设计使得单个攻击者就能对输出造成一定的影响,同时随着攻击方所控制的参与者数目增多,他们的破坏性也随之增强。
RANDAO VDFs
要增强 RANDAO 的公平性,其中一种办法是替换掉最后的那个异或计算,将其改变为执行时间必定长于各方随机数揭露等待期的操作。如果计算最终结果的时间比随机数揭露等待期要长,那么恶意攻击者就无法预先知道自身随机数揭露与否能给自己带来好处,因此理论上就无法影响最终结果的属性了。
虽然需要有一个函数来拖延参与者生成最终结果的时间,但不能因此让随机数用户也耗费巨大的开销去验证所生成的随机数。因此,理想函数应该能让用户轻易验证系统生成的随机数,而无需重复之前的计算开销。
上述既需要长时间来计算,同时能轻易验证计算结果,并且对每一个输入都有着独一无二输出的函数正是可验证延迟函数(verifiable delay function ,可缩写作 VDF ),设计一个这样函数的工作委实艰巨。近来这一领域已经有所突破,比如这个和这个已经可以应用,当前以太坊就计划应用 RANDAO 和 VDF 来作为其随机性信标。除此之外,由于这种策略所具备的不可预测性和无偏见性,使得系统甚至能在仅有两个参与者在线的情况下依然具备活性(假设底层共识协议的在参与者如此稀少时仍能具备活性)。
VDF 虽好,但目前的最大挑战在于函数需要足够健壮,即使某些别有用心者花大价钱配置定制化硬件设备,也无法在揭露等待期结束之前计算出最终结果,理想情况是函数具备有足够威慑力的安全边际,例如延迟时间较揭露等待期拖长 10 倍。下图展示了系统中参与者采用定制化 ASIC 设备所发起的一次攻击,攻击者能够在各方揭露 RANDAO 承诺之前计算出最终会输出的随机数。攻击者依然能根据计算得到的随机数结果,以及最终结果对自身收益的利害关系,自主决定是否要揭露所掌握的随机数。
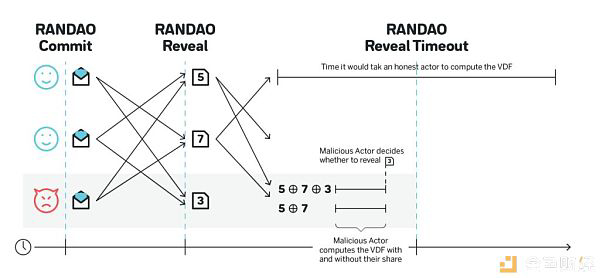
和 VDF 家族关联的特制 ASIC 设备会比传统硬件的计算速度快 100 倍。因此,如果揭露等待期耗时 10 秒,同时为了达成理想的 10 倍安全边际,需要保证 ASIC 设备至少花 100 秒才计算出最终结果,由此换算到普通硬件设备上则需 100 x 100 秒,即约 3 个小时来得到输出结果。
针对这一问题,以太坊基金会的做法是设计自己的 ASIC 设备并开源。一旦上述设想落地,以太坊之外的其它协议也能把真正的随机数用起来了。不给过在那个时刻到来之前,无力投资研发自己 ASIC 设备的协议们还是没法应用 RANDAO VDF 的解决方案。
这个网站收录了许多关于 VDF 的文章、视频以及其它资讯。
门限签名
Dfinity 团队正倡导并研究的的门限 BLS 签名是随机性的又一实现方案。(题外话,Dfinity 的研究员 Ben Lynn 就是 BLS 中的 L 本尊)
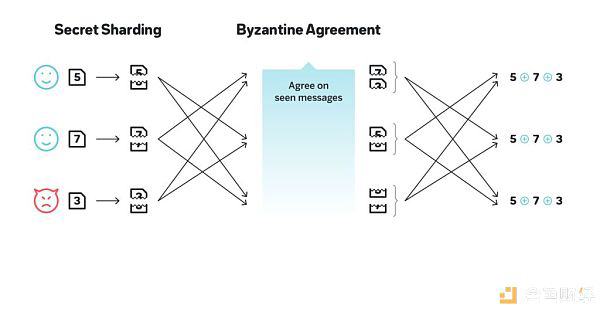
BLS 签名用于多方对一则消息构建一条聚合签名,由于无需额外的签名通信,因此常用于节省空间和带宽。在区块链里,BFT 共识协议的区块签名通常就使用 BLS 签名。例如在一个有 100 个节点的区块链系统中,当其中的 67 个节点都对某个区块进行了签名时,就可以认定这个区块已经上链。每一个节点都可以提交自己那片 BLS 签名,系统根据某些共识算法选出其中 67 片签名来聚合成一条 BLS 签名。虽然任意 67 片签名都能组成一条聚合签名,但不同的签名输入不会聚合成相同的 BLS 签名。
其实如果系统中参与者持有的私钥是通过某种特殊方式生成的,那无论选择哪 67 片(可以更多,但不能更少)签名,都能输出一样的聚合签名。这种特性可以用来产生随机性:系统中参与者首先对某则他们未来会进行签名的信息达成一致(可以是 RANDAO 的输出,也可以是最近一个区块的哈希,只要是每次都不一样的值就可以了),然后就此产生一个聚合签名。在 67 个参与者揭露自身签名之前,没有人能预测输出结果,同时由于大家在第一片签名披露之前就认定完了输出结果,因此任何参与者都无法再对输出产生影响。
上述随机性实现方案具备无偏见性和不可预测性,只要网络中有 2/3 参与者在线就能维持运行(这个门限当然也可以设置成其它数值)。即使 1/3 的节点掉线或篡谋发起攻击,他们也只能让系统停滞,因为要想对最终结果产生影响,需要至少 2/3 的节点。
看起来一切都很完美,但是,依然有一个但是。前文我曾提及私钥需要按某种特殊方式生成,这种被称为分布式密钥生成的技术(常简称为 DKG )事实上十分复杂并且仍处于探索阶段。在最近的一些公开演讲中,Dfinity 提出了使用 zk-SNARKs 来实现 DKG,但是 zk-SNARKs 十分复杂,并且这种构造方法还没有经过时间检验。总的来说,门限签名和 DKG 技术尚未发展到能落地应用的阶段。
RandShare
目前为止,NEAR 受到的最大影响来自于另一种算法:RandShare 。
RandShare 是一个无偏见且不可预测的协议,支持 1/3 恶意节点容错。其速度相对较慢,在对应论文中虽然提到了 RandHound 和 RandHerd 两种加速方法,然而和 RandShare 本身相比还是太过复杂,我们想要的理想协议应该简洁优美。
除了较大的通信压力(各节点需要进行 O(n^3) 级别的消息通信),RandShare 面临的另一个问题在于虽然 1/3 的容错门限能保证协议在应用中的活性,但这个门限难以震慑别有用心者对输出结果发起攻击。具体原因有以下几点:
攻击输出结果所带来的收益要远远大于拖滞随机数生成带来的收益。
如果某一方控制了 RandShare 中超过 1/3 的节点并试图操纵输出结果,这种攻击甚至不会留下任何痕迹。与光天化日之下拖滞随机数生成相比,操纵输出结果根本就是闷声发大财。
从现实考量,某势力操纵超过 1/3 的 哈希算力/权益 并非天方夜谭,而且根据(1)(2)两点,具备实力的攻击者基本不会选择拖滞随机数生成,而是倾向于暗地操纵输出结果。
NEAR 方案
我们最近发表的一篇论文介绍了 NEAR 方案。这是一个无偏见且不可预测的协议,其活性具备 1/3 节点的容错能力,即攻击方只有控制了全局 1/3 及以上的节点才能阻塞协议。
然而和 RandShare 不同,NEAR 能保证 2/3 恶意节点的容错。这个门限对实际应用来说显然更为优越。
NEAR 协议的核心思想如下(为了方便表述,此处假设正好有 100 个节点):
每一个节点首先提出自己的输出片,将其分成 67 份,再用纠删码将其编码为 100 份,这一过程需要保证任意 67 份数据都可以恢复输出片,然后使用其它各节点的公钥对每一份数据签名并转发,这样一来,各节点互相持有加密片。
系统中各节点使用某种共识算法(例如 Tendermint)选出特定 67 个节点所生成的加密片。
一旦达成共识,各个节点根据步骤 (2) 的结果,从本地取出被自身公钥签名过的加密片,解码揭露数据后立即广播。
一旦有 67 个节点完成了步骤 (3) ,系统就有了足够的信息解码重构出原始数据,最终结果可以由 (1) 中各节点输出片的简单异或操作得到。
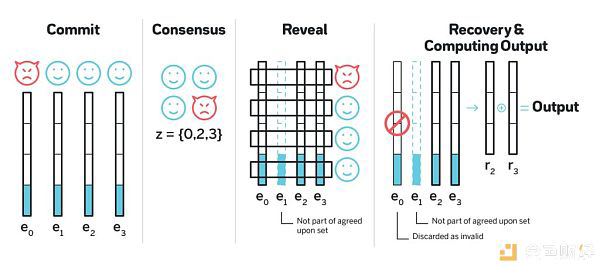
上述协议具备无偏见性和不可预测性的道理和 RandShare 以及门限签名都类似:一旦达成共识,输出已经被确定了,只不过要等到至少 2/3 的节点用各自公钥将加密的那部分揭露,大家才能看到输出结果。
如果要考虑一些特殊情况以及可能的恶意攻击,协议可能变得稍稍复杂(举例来说,如果步骤(1)中有节点生成无效的纠删码,系统需要有能力应对),但总的来说整个协议还是十分清爽,涵盖了所有证明和相关密码学原语和引用的论文篇幅仅 7 页长。如果你想了解算法更为规范的描述,或是对其活性和防御性的分析,请务必阅读我们的论文。
当前 NEAR 协议架构已经应用了类似的纠删码思想,系统中区块生产者会在特定时期内创建一些分块,其中包含了对于某一特定分片的所有交易,然后将分块进行纠删码编码后的版本附带默尔克证明发送给其它区块生产者,以保证数据可用性。(点击此处阅读我们分片论文的 3.4 节)
结语
我们正在努力编写一组主题为区块链协议及相关内容的高质量技术文章,本文是其中一篇。除此之外,我们还制作了一系列面向其它协议创始人和核心开发者的视频,目前已经录制了针对包括 Ethereum Serenity、Cosmos、Polkadot、Ontology、QuarkChain 在内多个项目的视频。为了便于查看,所有视频都已经被打包进了这个播放列表。
如果你对 NEAR 协议背后的技术感兴趣,请务必研读上文提到的那篇分片论文。NEAR 是少数几个在分片中解决状态验证和数据可用性矛盾的协议,并且该论文在给出我们的解决方案之外,还提供了一个针对分片的更为开阔、通用的视角。
今时今日,虽然扩容是区块链中的大挑战,但可用性难题或许更值得大家关注。我们团队对此倾注了大量资源,努力构建更可用的区块链系统。最近我们发表了一篇概览,介绍了当今区块链协议面临的种种可用性挑战,以及对应的探索路线。
Twitter 关注,不迷路!也欢迎来我们的 Discord 频道畅所欲言,无论是技术、经济、治理或是协议设计中的其它方方面面,我们都会进行热烈而精彩的讨论。
(完)
(文内提供了许多超链接,请点击阅读原文到 EthFans 网站上获取)
原文链接:
https://nearprotocol.com/blog/randomness-in-blockchain-protocols/
作者: Alexander Skidanov
翻译 & 校对: 安仔 Clint & 阿剑
本文由作者授权 EthFans 翻译及再出版。