Gate Ventures:AI x Crypto从入门到精通(上)
分享到朋友或朋友圈

引言
AI 行业近期的发展,被一部分人视为第四次工业革命,大模型的出现显著提升了各行各业的效率, 波士顿咨询认为 GPT 为美国提升了大约 20% 的工作效率。同时大模型带来的泛化能力被喻为新的软件设计范式,过去软件设计是精确的代码,现在的软件设计是更泛化的大模型框架嵌入到软件中,这些软件能具备更好的表现和支持更广泛模态输入与输出。深度学习技术确实为 AI 行业带来了第四次繁荣,并且这一股风潮也弥漫到了 Crypto 行业。
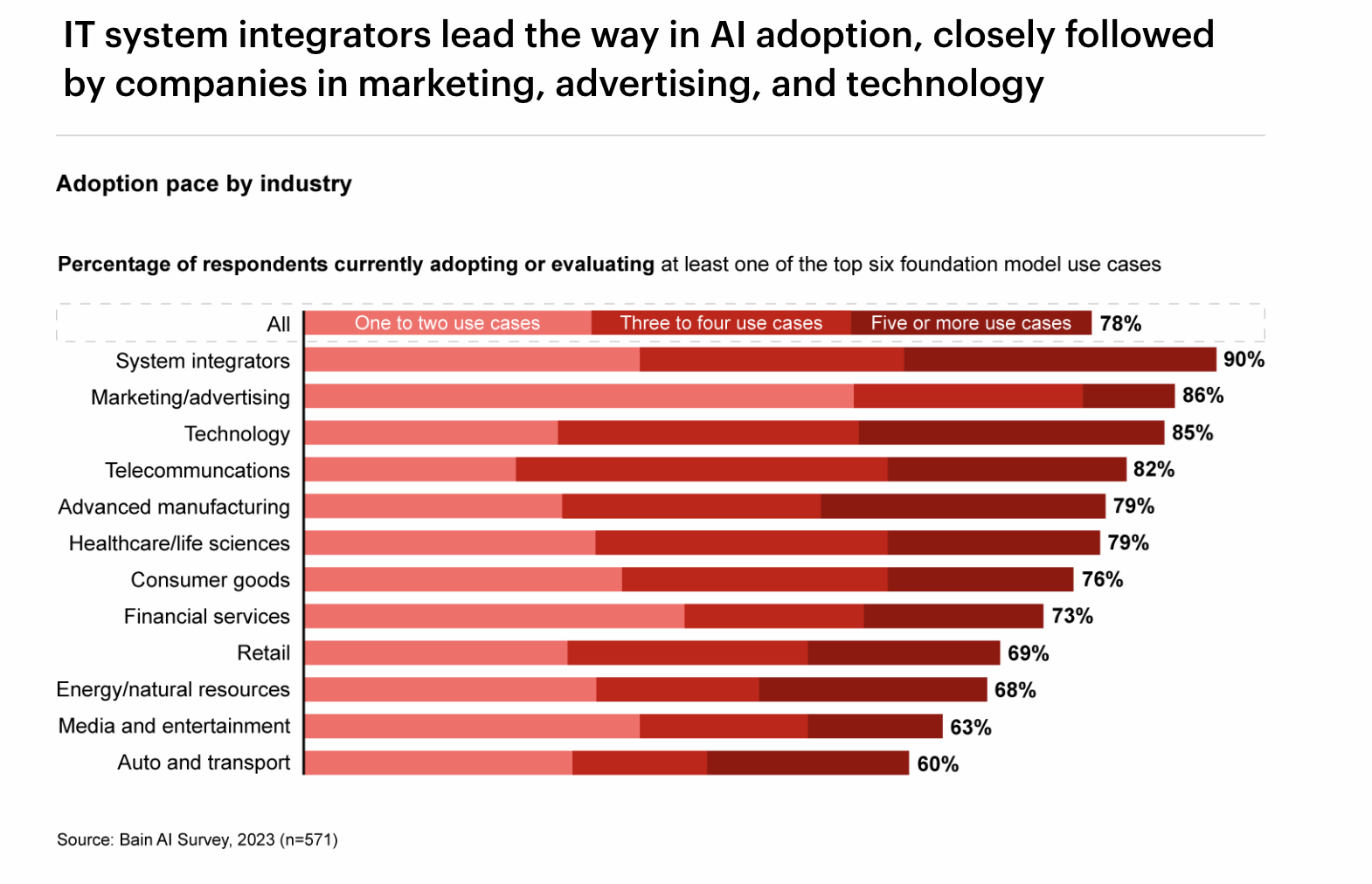
Bain AI Survey
在本报告中,我们将详细探讨 AI 行业的发展历史、技术分类、以及深度学习技术的发明对行业的影响。然后深度剖析深度学习中 GPU、云计算、数据源、边缘设备等产业链上下游,以及其发展现状与趋势。之后我们从本质上详细探讨了 Crypto 与 AI 行业的关系,对于 Crypto 相关的 AI 产业链的格局进行了梳理。
Microsoft
现代人工智能技术使用的主要是“机器学习”这一术语,该技术的理念是让机器依靠数据在任务中反复迭代以改善系统的性能。主要的步骤是将数据送到算法中,使用此数据训练模型,测试部署模型,使用模型以完成自动化的预测任务。
目前机器学习有三大主要的流派,分别是联结主义、符号主义和行为主义,分别模仿人类的神经系统、思维、行为。
Cloudflare
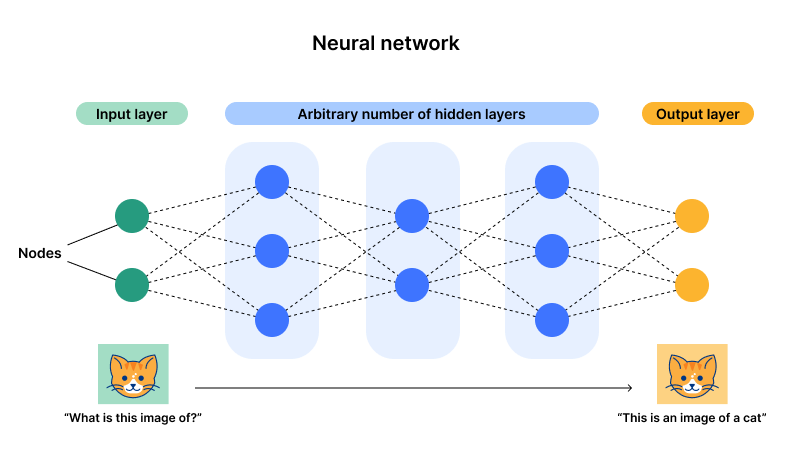
而目前以神经网络为代表的联结主义占据上风(也被称为深度学习),主要原因是这种架构有一个输入层一个输出层,但是有多个隐藏层,一旦层数以及神经元(参数)的数量变得足够多,那么就有足够的机会拟合复杂的通用型任务。通过数据输入,可以一直调整神经元的参数,那么最后经历过多次数据,该神经元就会达到一个最佳的状态(参数),这也就是我们说的大力出奇迹,而这也是其“深度”两字的由来——足够多的层数和神经元。
举个例子,可以简单理解就是构造了一个函数,该函数我们输入 X= 2 时,Y= 3 ;X= 3 时,Y= 5 ,如果想要这个函数应对所有的 X,那么就需要一直添加这个函数的度及其参数,比如我此时可以构造满足这个条件的函数为 Y = 2 X -1 ,但是如果有一个数据为 X= 2, Y= 11 时,就需要重构一个适合这三个数据点的函数,使用 GPU 进行暴力破解发现 Y = X 2 -3 X 5 ,比较合适,但是不需要完全和数据重合,只需要遵守平衡,大致相似的输出即可。这里面 X 2 以及 X、X 0 都是代表不同的神经元,而 1、-3、 5 就是其参数。
此时如果我们输入大量的数据到神经网络中时,我们可以增加神经元、迭代参数来拟合新的数据。这样就能拟合所有的数据。
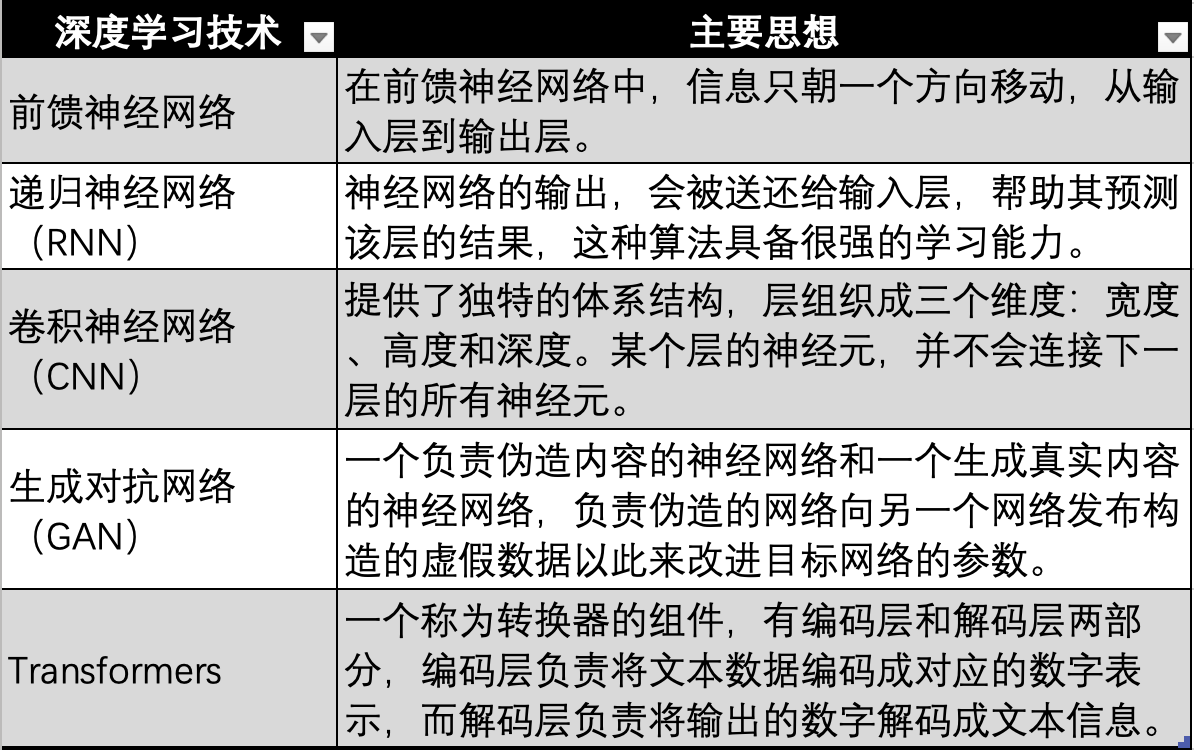
深度学习技术演进,图源:Gate Ventures
而基于神经网络的深度学习技术,也有多个技术迭代与演进,分别如上图的最早期的神经网络,前馈神经网络、RNN、CNN、GAN 最后演进到现代大模型如 GPT 等使用的 Transformer 技术,Transformer 技术只是神经网络的一个演进方向,多加了一个转换器(Transformer),用于把所有模态(如音频,视频,图片等)的数据编码成对应的数值来表示。然后再输入到神经网络中,这样神经网络就能拟合任何类型的数据,也就是实现多模态。
AI 发展经历了三次技术浪潮,第一次浪潮是 20 世纪 60 年代,是 AI 技术提出的十年后,这次浪潮是符号主义技术发展引起的,该技术解决了通用的自然语言处理以及人机对话的问题。同时期,专家系统诞生,这个是斯坦福大学在美国国家航天局的督促下完成的 DENRAL 专家系统,该系统具备非常强的化学知识,通过问题进行推断以生成和化学专家一样的答案,这个化学专家系统可以被视为化学知识库以及推断系统的结合。
在专家系统之后, 20 世纪 90 年代以色列裔的美国科学家和哲学家朱迪亚·珀尔(Judea Pearl)提出了贝叶斯网络,该网络也被称为信念网络。同时期,Brooks 提出了基于行为的机器人学,标志着行为主义的诞生。
1997 年,IBM 深蓝“Blue”以 3.5: 2.5 战胜了国际象棋冠军卡斯帕罗夫(Kasparov),这场胜利被传视为人工智能的一个里程碑,AI 技术迎来了第二次发展的高潮。
第三次 AI 技术浪潮发生在 2006 年。深度学习三巨头 Yann LeCun、Geoffrey Hinton 以及 Yoshua Bengio 提出了深度学习的概念,一种以人工神经网络为架构,对资料进行表征学习的算法。之后深度学习的算法逐渐演进,从 RNN、GAN 到 Transformer 以及 Stable Diffusion,这两个算法共同塑造了这第三次技术浪潮,而这也是联结主义的鼎盛时期。
许多标志性的事件也伴随着深度学习技术的探索与演进逐渐涌现,包括:
● 2011 年,IBM 的沃森(Watson)在《危险边缘》(Jeopardy)回答测验节目中战胜人类、获得冠军。
● 2014 年,Goodfellow 提出 GAN(生成式对抗网络,Generative Adversarial Network),通过让两个神经网络相互博弈的方式进行学习,能够生成以假乱真的照片。同时 Goodfellow 还写了一本书籍《Deep Learning》,称为花书,是深度学习领域重要入门书籍之一。
● 2015 年,Hinton 等人在《自然》杂志提出深度学习算法,该深度学习方法的提出,立即在学术圈以及工业界引起巨大反响。
● 2015 年,OpenAI 创建,Musk、YC 总裁 Altman、天使投资人彼得·泰尔(Peter Thiel)等人宣布共同注资 10 亿美元。
● 2016 年,基于深度学习技术的 AlphaGo 与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以 4 比 1 的总比分获胜。
● 2017 年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,其称为历史上首个获得一等公民身份的机器人,具备丰富的面部表情以及人类语言理解能力。
● 2017 年,在人工智能领域有丰富人才、技术储备的 Google 发布论文《Attention is all you need》提出 Transformer 算法,大规模语言模型开始出现。
● 2018 年,OpenAI 发布了基于 Transformer 算法构建的 GPT(Generative Pre-trained Transformer),这是当时最大的语言模型之一。
● 2018 年,Google 团队 Deepmind 发布基于深度学习的 AlphaGo,能够进行蛋白质的结构预测,被视为人工智能领域的巨大进步性标志。
● 2019 年,OpenAI 发布 GPT-2 ,该模型具备 15 亿个参数。
● 2020 年,OpenAI 开发的 GPT-3 ,具有 1, 750 亿个参数,比以前的版本 GPT-2 高 100 倍,该模型使用了 570 GB 的文本来训练,可以在多个 NLP(自然语言处理)任务(答题、翻译、写文章)上达到最先进的性能。
● 2021 年,OpenAI 发布 GPT-4 ,该模型具备 1.76 万亿个参数,是 GPT-3 的 10 倍。
● 2023 年 1 月基于 GPT-4 模型的 ChatGPT 应用程序推出, 3 月 ChatGPT 达到一亿用户,成为历史最快达到一亿用户的应用程序。
● 2024 年,OpenAI 推出 GPT-4 omni。
WaytoAI
首先我们需要明晰的是,在进行基于 Transformer 技术的 GPT 为首的 LLMs(大模型)训练时,一共分为三个步骤。
在训练之前,因为是基于 Transformer,因此转换器需要将文本输入转化为数值,这个过程被称为“Tokenization”,之后这些数值被称为 Token。在一般的经验法则下,一个英文单词或者字符可以粗略视作一个 Token,而每个汉字可以被粗略视为两个 Token。这个也是 GPT 计价使用的基本单位。
第一步,预训练。通过给输入层足够多的数据对,类似于报告第一部分所举例的(X,Y),来寻找该模型下各个神经元最佳的参数,这个时侯需要大量的数据,而这个过程也是最耗费算力的过程,因为要反复迭代神经元尝试各种参数。一批数据对训练完成之后,一般会使用同一批数据进行二次训练以迭代参数。
第二步,微调。微调是给予一批量较少,但是质量非常高的数据,来训练,这样的改变就会让模型的输出有更高的质量,因为预训练需要大量数据,但是很多数据可能存在错误或者低质量。微调步骤能够通过优质数据提升模型的品质。
第三步,强化学习。首先会建立一个全新的模型,我们称其为“奖励模型”,这个模型目的非常简单,就是对输出的结果进行排序,因此实现这个模型会比较简单,因为业务场景比较垂直。之后用这个模型来判定我们大模型的输出是否是高质量的,这样就可以用一个奖励模型来自动迭代大模型的参数。(但是有时候也需要人为参与来评判模型的输出质量)
简而言之,在大模型的训练过程中,预训练对数据的量有非常高的要求,所需要耗费的 GPU 算力也是最多的,而微调需要更加高质量的数据来改进参数,强化学习可以通过一个奖励模型来反复迭代参数以输出更高质量的结果。
在训练的过程中,参数越多那么其泛化能力的天花板就越高,比如我们以函数举例的例子里,Y = aX b,那么实际上有两个神经元 X 以及 X 0 ,因此参数如何变化,其能够拟合的数据都极其有限,因为其本质仍然是一条直线。如果神经元越多,那么就能迭代更多的参数,那么就能拟合更多的数据,这就是为什么大模型大力出奇迹的原因,并且这也是为什么通俗取名大模型的原因,本质就是巨量的神经元以及参数、巨量的数据,同时需要巨量的算力。
因此,影响大模型表现主要由三个方面决定,参数数量、数据量与质量、算力,这三个共同影响了大模型的结果质量和泛化能力。我们假设参数数量为 p,数据量为 n(以 Token 数量进行计算),那么我们能够通过一般的经验法则计算所需的计算量,这样就可以预估我们需要大致购买的算力情况以及训练时间。
算力一般以 Flops 为基本单位,代表了一次浮点运算,浮点运算是非整数的数值加减乘除的统称,如 2.5 3.557 ,浮点代表着能够带小数点,而 FP 16 代表了支持小数的精度,FP 32 是一般更为常见的精度。根据实践下的经验法则,预训练(Pre-traning)一次(一般会训练多次)大模型,大概需要 6 np Flops, 6 被称为行业常数。而推理(Inference,就是我们输入一个数据,等待大模型的输出的过程),分成两部分,输入 n 个 token,输出 n 个 token,那么大约一共需要 2 np Flops。
在早期,使用的是 CPU 芯片进行训练提供算力支持,但是之后开始逐渐使用 GPU 替代,如 Nvidia 的 A 100、H 100 芯片等。因为 CPU 是作为通用计算存在的,但是 GPU 可以作为专用的计算,在能耗效率上远远超过 CPU。GPU 运行浮点运算主要是通过一个叫 Tensor Core 的模块进行。因此一般的芯片有 FP 16 / FP 32 精度下的 Flops 数据,这个代表了其主要的计算能力,也是芯片的主要衡量指标之一。
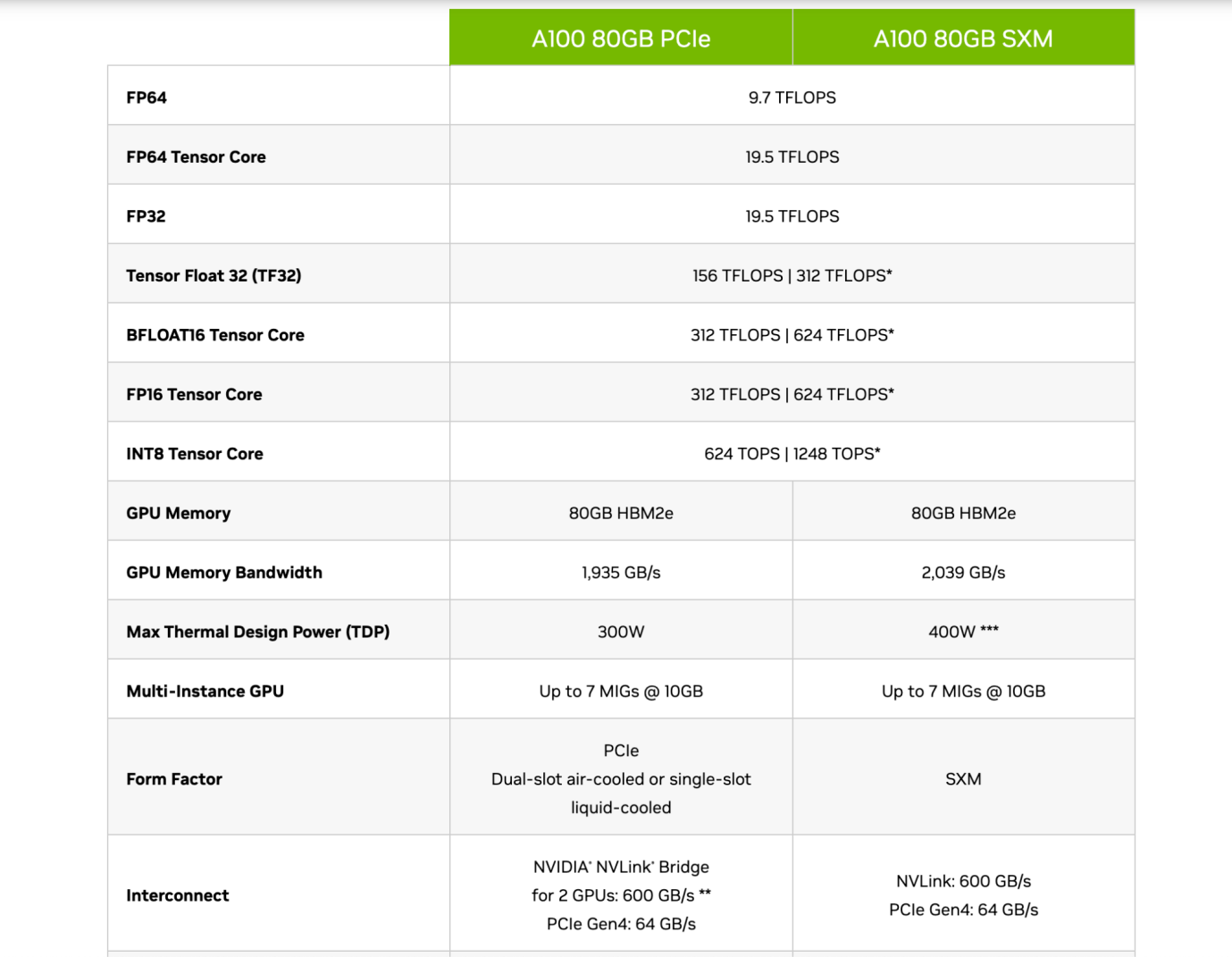
Nvidia
因此读者应该能够看懂这些企业的芯片介绍,如上图所示,Nvidia 的 A 100 80 GB PCIe 和 SXM 型号的对比中,看出 PCIe 和 SXM 在 Tensor Core(专门用于计算 AI 的模块)下,在 FP 16 精度下,分别是 312 TFLOPS 和 624 TFLOPS(Trillion Flops)。
假设我们的大模型参数以 GPT 3 为例,有 1750 亿个参数, 1800 亿个 Token 的数据量(大约为 570 GB),那么在进行一次预训练时,就需要 6 np 的 Flops,大约为 3.15* 1022 Flops,如果以 TFLOPS(Trillion FLOPs)为单位大约为 3.15* 1010 TFLOPS,也就是说一张 SXM 型号的芯片预训练一次 GPT 3 大约需要 50480769 秒, 841346 分钟, 14022 小时, 584 天。
我们能够看到这个及其庞大的计算量,需要多张最先进的芯片共同计算才能够实现一次预训练,并且 GPT 4 的参数量又是 GPT 3 的十倍(1.76 trillion),意味着即使数据量不变的情况下,芯片的数量要多购买十倍,并且 GPT-4 的 Token 数量为 13 万亿个,又是 GPT-3 的十倍,最终,GPT-4 可能需要超过 100 倍的芯片算力。
在大模型训练中,我们的数据存储也有问题,因为我们的数据如 GPT 3 Token 数量为 1800 亿个,大约在存储空间中占据 570 GB,大模型 1750 亿个参数的神经网络,大约占据 700 GB 的存储空间。GPU 的内存空间一般都较小(如上图介绍的 A 100 为 80 GB),因此在内存空间无法容纳这些数据时,就需要考察芯片的带宽,也就是从硬盘到内存的数据的传输速度。同时由于我们不会只使用一张芯片,那么就需要使用联合学习的方法,在多个 GPU 芯片共同训练一个大模型,就涉及到 GPU 在芯片之间传输的速率。所以在很多时候,制约最后模型训练实践的因素或者成本,不一定是芯片的计算能力,更多时侯可能是芯片的带宽。因为数据传输很慢,会导致运行模型的时间拉长,电力成本就会提高。

Nvidia
这个时侯,读者大致就能完全看懂芯片的 Specification 了,其中 FP 16 代表精度,由于训练 AI LLMs 主要使用的是 Tensor Core 组件,因此只需要看这个组件下的计算能力。FP 64 Tensor Core 代表了在 64 精度下每秒 H 100 SXM 能够处理 67 TFLOPS。GPU memory 意味着芯片的内存仅有 64 GB,完全无法满足大模型的数据存储要求,因此 GPU memory bandwith 就意味着数据传输的速度,H 100 SXM 为 3.35 TB/s。
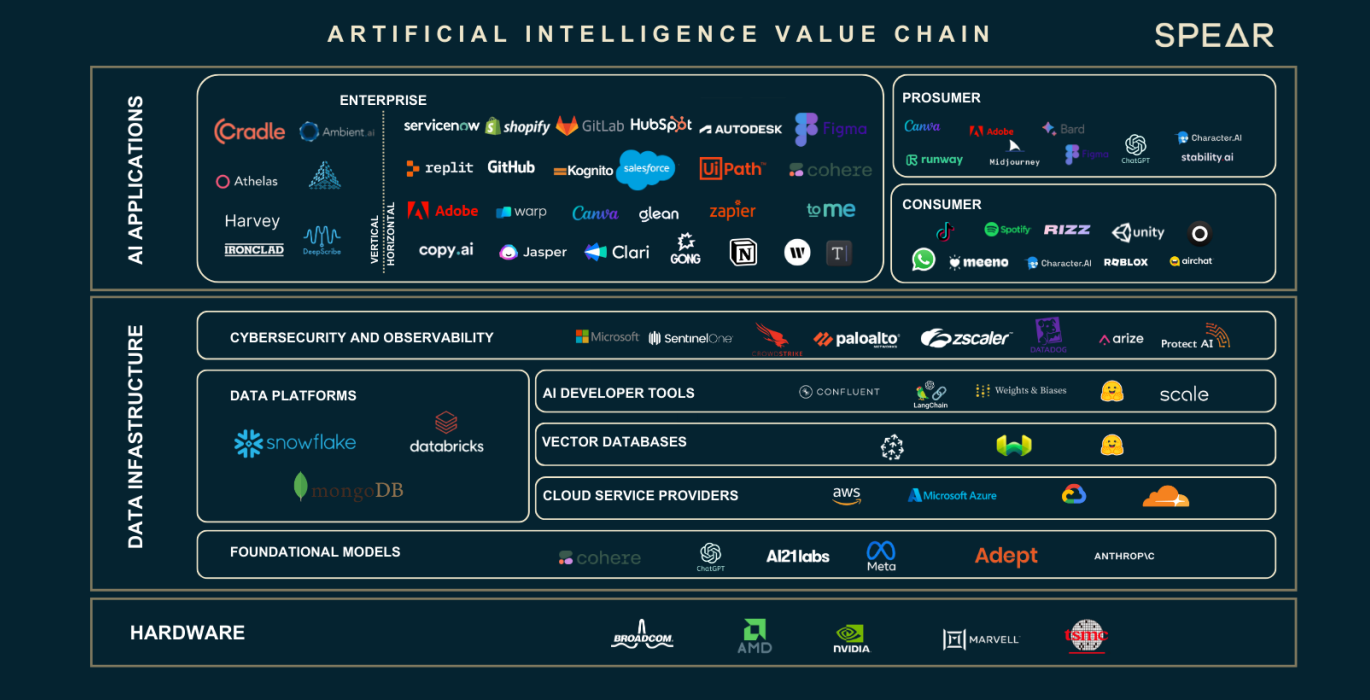
硬件 GPU 提供商
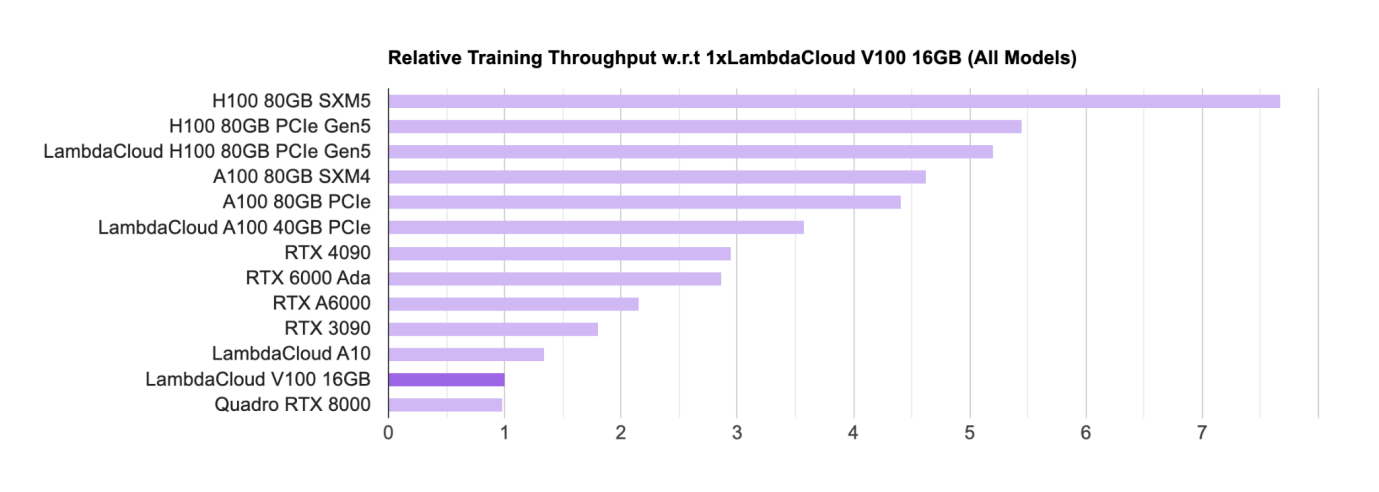
Lambda
硬件如 GPU 是目前进行训练和推理的主要芯片,对于 GPU 芯片的主要设计商方面,目前 Nvidia 处于绝对的领先地位,学术界(主要是高校和研究机构)主要是使用消费级别的 GPU(RTX,主要的游戏 GPU);工业界主要是使用 H 100、 A 100 等用于大模型的商业化落地。
在榜单中,Nvidia 的芯片几乎屠榜,所有芯片都来自 Nvidia。Google 也有自己的 AI 芯片被称为 TPU,但是 TPU 主要是 Google Cloud 在使用,为 B 端企业提供算力支持,自购的企业一般仍然倾向于购买 Nvidia 的 GPU。
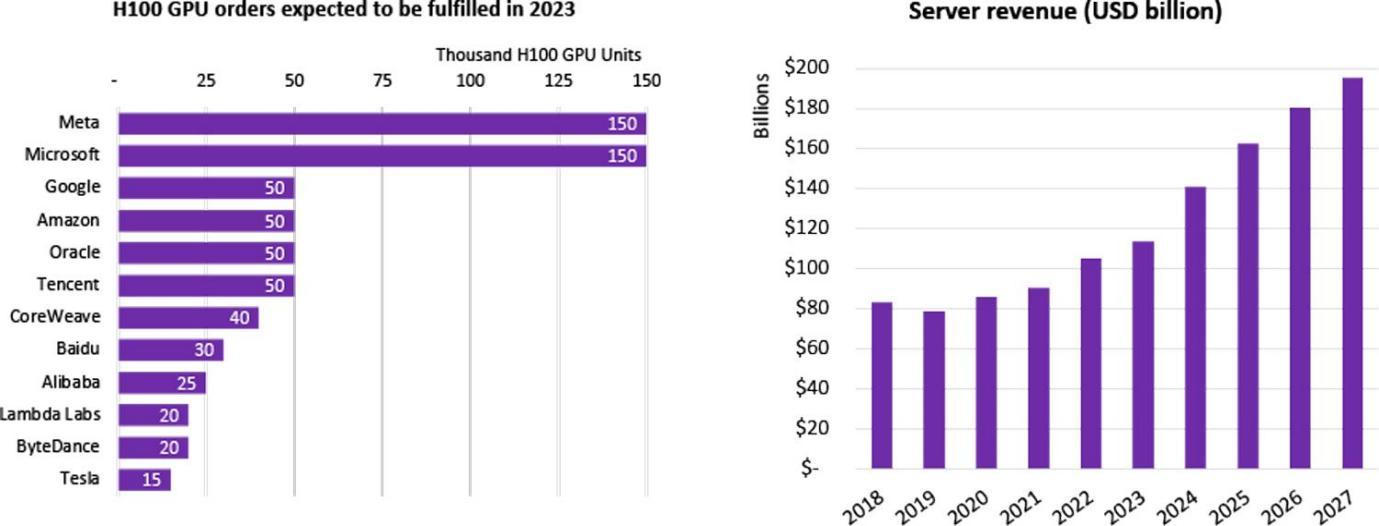
Omdia
大量的企业着手进行 LLMs 的研发,包括中国就有超过一百个大模型,而全球一共发行了超过 200 个大语言模型,许多互联网巨头都在参与这次 AI 热潮。这些企业要么是自购大模型、要么是通过云企业进行租赁。2023 年,Nvidia 最先进的芯片 H 100 一经发布,就获得了多家公司的认购。全球对 H 100 芯片的需求远远大于供给,因为目前仅仅只有 Nvidia 一家在供给最高端的芯片,其出货周期已经达到了惊人的 52 周之久。
鉴于 Nvidia 的垄断情况,Google 作为人工智能的绝对领头企业之一,谷歌牵头,英特尔、高通、微软、亚马逊共同成立了 CUDA 联盟,希望共同研发 GPU 以摆脱 Nvidia 对深度学习产业链的绝对影响力。
对于 超大型科技公司/云服务提供商/国家级实验室来说,他们动则购买上千、上万片 H 100 芯片,用以组建 HPC(高性能计算中心),比如 Tesla 的 CoreWeave 集群购买了一万片 H 100 80 GB,平均购买价为 44000 美元(Nvidia 成本大约为 1/10),总共花费 4.4 亿美元;而 Tencent 更是购买 5 万片;Meta 狂买 15 万片,截至 2023 年底,Nvidia 作为唯一高性能 GPU 卖家,H 100 芯片的订购量就超过了 50 万片。
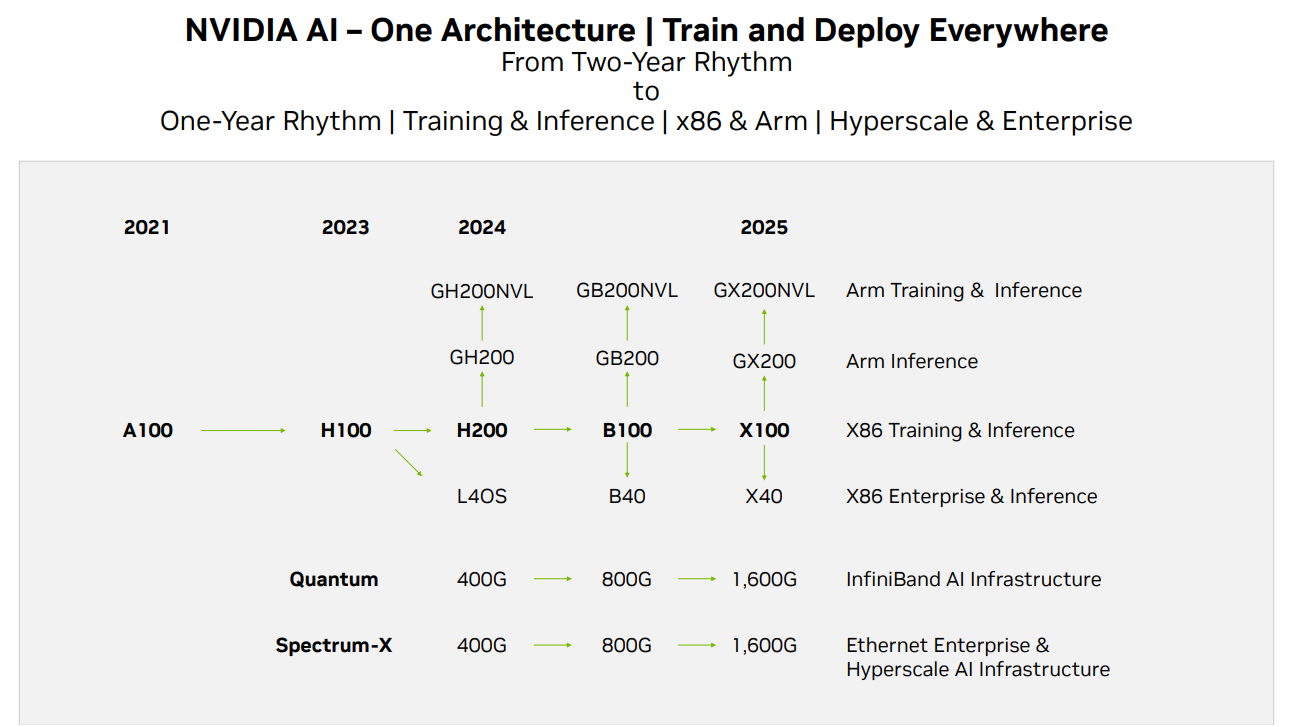
Techwire
在 Nvidia 的芯片供给方面,以上是其产品迭代路线图,目前截至该报告,H 200 的消息已经发出,预计 H 200 的性能是 H 100 性能的两倍,而 B 100 将在 2024 年底或者 2025 年初推出。目前 GPU 的发展仍然满足摩尔定律,性能每 2 年翻一倍,价格下降一半。
Salesforce Ventures
云服务提供商在购买足够的 GPU 组建 HPC 后,能够为资金有限的人工智能企业提供弹性的算力以及托管训练解决方案。如上图所示,目前市场主要分为三类云算力提供商,第一类是以传统云厂商为代表的超大规模拓展的云算力平台(AWS、Google、Azure)。第二类是垂直赛道的云算力平台,主要是为 AI 或者高性能计算而布置的,他们提供了更专业的服务,因此在与巨头竞争中,仍然存在一定的市场空间,这类新兴垂直产业云服务企业包括 CoreWeave(C 轮获得 11 以美元融资,估值 190 亿美元)、Crusoe、Lambda(C 轮融资 2.6 亿美元,估值超过 15 亿美元)等。第三类云服务提供商是新出现的市场玩家,主要是推理即服务提供商,这些服务商从云服务商租用 GPU,这类服务商主要为客户部署已经预训练完毕的模型,在之上进行微调或者推理,这类市场的代表企业包括了 Together.ai(最新估值 12.5 亿美元)、Fireworks.ai(Benchmark 领投,A 轮融资 2500 万美元)等。
训练数据源提供商
正如我们第二部分前面所述,大模型训练主要经历三个步骤,分别为预训练、微调、强化学习。预训练需要大量的数据,微调需要高质量的数据,因此对于 Google 这种搜索引擎(拥有大量数据)和 Reddit(优质的对答数据)这种类型的数据公司就受到市场的广泛关注。
有些开发厂商为了不与 GPT 等通用型的大模型竞争,选择在细分领域进行开发,因此对数据的要求就变成了这些数据是特定行业的,比如金融、医疗、化学、物理、生物、图像识别等。这些是针对特定领域的模型,需要特定领域的数据,因此就存在为这些大模型提供数据的公司,我们也可以叫他们 Data labling company,也就是为采集数据后为数据打标签,提供更加优质与特定的数据类型。
对于模型研发的企业来说,大量数据、优质数据、特定数据是三种主要的数据诉求。
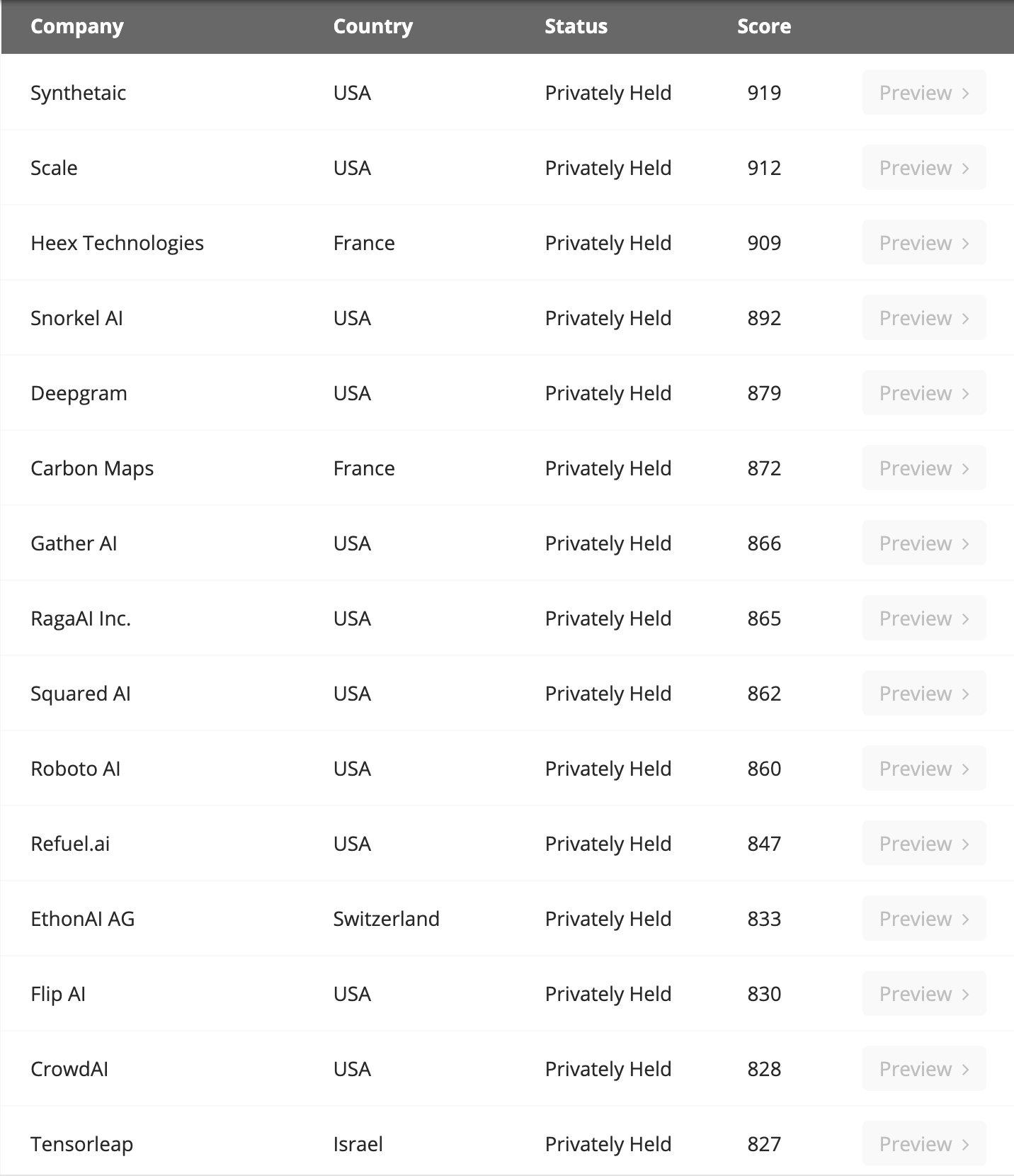
Venture Radar
微软的一项研究认为对于 SLM(小语言模型)来说,如果他们的数据质量明显优于大语言模型,那么其性能不一定会比 LLMs 差。并且实际上 GPT 在原创力以及数据上并没有明显的优势,主要是其对该方向的押注的胆量造就了其成功。红杉美国也坦言,GPT 在未来不一定会保持竞争优势,原因是目前这方面没有太深的护城河,主要的限制来源于算力获取的限制。
对于数据量来说,根据 EpochAI 的预测,按照当前的模型规模增长情况, 2030 年所有的低质量和高质量数据都会耗尽。所以目前业内正在探索人工智能合成数据,这样就可以生成无限的数据,那么瓶颈就只剩下算力,这个方向仍然处于探索阶段,值得开发者们关注。
数据库提供商
我们有了数据,但是数据也需要存储起来,一般是存放在数据库中,这样方便数据的增删改查。在传统的互联网业务中,我们可能听说过 MySQL,在以太坊客户端 Reth 中,我们听说过 Redis。这些都是我们存放业务数据或者区块链 链上数据的本地数据库。对于不同的数据类型或者业务有不同的数据库适配。
对于 AI 数据以及深度学习训练推理任务,目前业内使用的数据库称为“矢量数据库”。矢量数据库旨在高效地存储、管理和索引海量高维矢量数据。因为我们的数据并不是单纯的数值或者文字,而是图片、声音等海量的非结构化的数据,矢量数据库能够将这些非结构化的数据统一以“向量”的形式存储,而矢量数据库适合这些向量的存储和处理。

Yingjun Wu
目前主要的玩家有 Chroma(获得 1800 万美元融资轮融资)、Zilliz(最新一轮融资 6000 万美元)、Pinecone、Weaviate 等。我们预计伴随着数据量的需求增加,以及各种细分领域的大模型和应用的迸发,对 Vector Database 的需求将大幅增加。并且由于这一领域有很强的技术壁垒,在投资时更多考虑偏向于成熟和有客户的企业。
边缘设备
在组建 GPU HPC(高性能计算集群)时,通常会消耗大量的能量,这就会产生大量的热能,芯片在高温环境下,会限制运行速度以降低温度,这就是我们俗称的“降频”,这就需要一些降温的边缘设备来保证 HPC 持续运行。
所以这里涉及到产业链的两个方向,分别是能源供应(一般是采用电能)、冷却系统。
目前在能源供给侧,主要是采用电能,数据中心及支持网络目前占全球电力消耗的 2% -3% 。BCG 预计随着深度学习大模型参数的增长以及芯片的迭代,截至 2030 年,训练大模型的电力将增长三倍。目前国内外科技厂商正在积极投资能源企业这一赛道,投资的主要能源方向包括地热能、氢能、电池存储和核能等。
在 HPC 集群散热方面,目前是以风冷为主,但是许多 VC 正在大力投资液冷系统,以维持 HPC 的平稳运行。比如 Jetcool 就声称其液冷系统能够为 H 100 集群的总功耗降低 15% 。目前液冷主要分成三个探索方向分别为冷版式液冷、浸没式液冷、喷淋式液冷。这方面的企业有:华为、Green Revolution Cooling、SGI 等。
A16Z
目前前十月活的 AI 应用大多数是搜索类型的应用,实际走出来的 AI 应用还非常有限,应用类型较为单一,并没有一些社交等类型的应用成功闯出来。
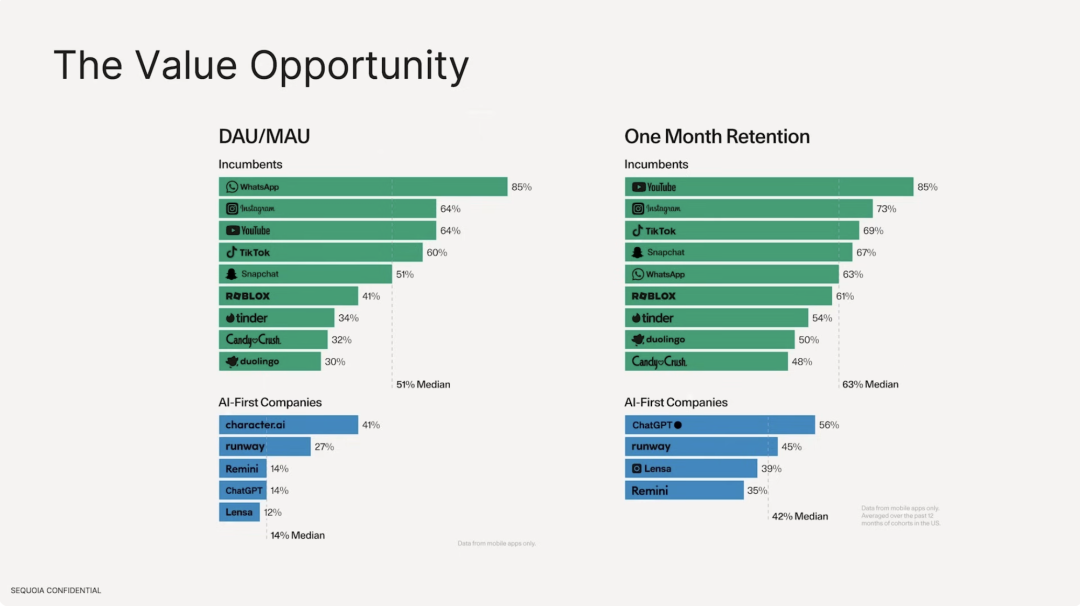
我们同时发现,基于大模型的 AI 应用,其留存率远低于现有的传统互联网应用。活跃用户数方面,传统的互联网软件中位数在 51% ,最高的是 Whatsapp,具备很强的用户粘性。但是在 AI 应用侧,DAU/MAU 最高的为 character.ai 仅仅为 41% ,DAU 占据总用户数量的中位数 14% 。在用户留存率方面,传统互联网软件最好的是 Youtube、Instagram、Tiktok,前十的留存率中位数为 63% ,相比之下 ChatGPT 留存率仅仅为 56% 。

Sequoia
根据红杉美国的报告,其将应用从面向的角色角度分为三类,分别是面向专业消费者、企业、普通消费者。
1. 面向消费者:一般用于提升生产力,如文字工作者使用 GPT 进行问答,自动化的3D渲染建模,软件剪辑,自动化的代理人,使用 Voice 类型的应用进行语音对话、陪伴、语言练习等。
2. 面向企业:通常是 Marketing、法律、医疗设计等行业。
虽然现在有很多人批评,基础设施远大于应用,但其实我们认为现代世界已经广泛的被人工智能技术所重塑,只不过使用的是推荐系统,包括字节跳动旗下的 tiktok、今日头条、汽水音乐等,以及小红书和微信视频号、广告推荐技术等都是为个人进行定制化的推荐,这些都属于机器学习算法。所以目前蓬勃发展的深度学习不完全代表 AI 行业,有许多潜在的有机会实现通用人工智能的技术也在并行发展,并且其中一些技术已经被广泛的应用于各行各业。
那么,Crypto x AI 之间发展出怎样的关系?Crypto 行业 Value Chain 又有哪些值得关注的项目?我们将在《Gate Ventures:AI x Crypto 从入门到精通(下)》为大家一一解读。
免责声明:
以上内容仅供参考,不应被视为任何建议。在进行投资前,请务必寻求专业建议。
关于 Gate Ventures
Gate Ventures 是 Gate.io 旗下的风险投资部门,专注于对去中心化基础设施、生态系统和应用程序的投资,这些技术将在 Web 3.0 时代重塑世界。Gate Ventures 与全球行业领袖合作,赋能那些拥有创新思维和能力的团队和初创公司,重新定义社会和金融的交互模式。
官网:https://ventures.gate.io/
Twitter:https://x.com/gate_ventures
Medium:https://medium.com/gate_ventures
