[区分精选] ENG: 数据隐私的领先者, 极力提升数据存储的效率和安全性
分享到朋友或朋友圈

区块链的提出,其面对的一个巨大需求是:数据的隐私计算。何为数据的隐私计算呢?其实就是将数据中涉及个人、机构等秘密不公开的数据权限归还给数据拥有者。例如,你的工资、财产、健康状况等不必要公开的信息归还给您保管,第三方无权获得。
然而,目前存在两个极大的矛盾:
(1)中心化的存储模式无法确保你的数据不泄露。
例如,Facebook存储了20多亿用户的数据,曾经出于主管意愿的售卖或者被动黑客攻击,发生数据泄露事件层出不穷。
(2)个体隐私数据不泄露,但群体的统计指标应该属于公共财产。
这是一个矛盾。你的隐私数据虽然应该归还给您,但是公共的数据指标却应该公开。例如,你的工资不应该公开,但每年中国需要统计人均收入水平,则需要每个人提供工资收入。所以,如何是好?
区块链的出现,看似为数据隐私提供了非常好的解决方案。通过对数据的层层加密后,然后公开必要的透明数据让每人可查。比如,我们不指明比特币两个交易账户之间的个人信息,但通过查询交易金额,我们可以查询比特币网络的每日平均交易额。
但是,仅仅做到层次,其实还不够,Enginma则提供了更为全面的隐私解决方案,助力区块链与大数据的结合。
解决方案
(1)链上和链下数据解决方案
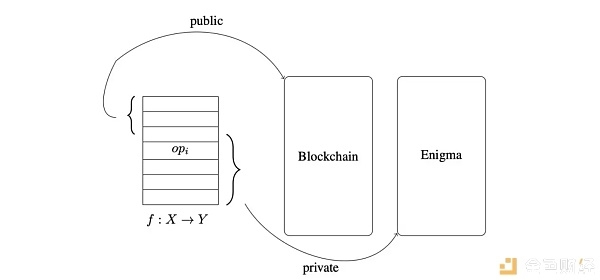
图解:Eng将数据分为链上存储的公开数据以及链下存储的隐私数据。
首先,我们需要意识到,Enigma本身是一种双层结构。代码在区块链(公共验证部分)和链下网络(隐私密集型的计算部分)上执行,从而确保了的执行方式确保了隐私和正确性。如白皮书中的图显示,对于数据中提供给公共验证部分,则直接存储在区块链上。对于大量蕴含隐私的数据,我们就进行链下正确计算后,将必要的公开数据存储到链上即可,剩余隐私部分则存储到各个节点。
这样的好处在于,这样能保证区块链的数据效率。一方面来说,目前区块链性能并不满足大规模的数据计算与存储,因此,只将必要的数据上链,这能提高区块链的效率。另一方面,对于链下存储部分,不仅能够高速运行,还能提升数据的隐私保护程度,增加大规模数据落地的可能性。
(2)链下数据治理方案
首先,数据链下治理我们分为存储和隐私计算。
我们假设一个医院的病患病历信息库在Enigma开展链下存储和计算,将会发生类似的情况。利用链下节点,Enigma为医患库建立一个分布式数据库。但是不同区块链的解决方案,每个节点只能随机存储每个医患的部分信息。这样,不仅能够确保每个节点能大大提高存储的效率,还能确保一个事情:每个节点存储的数据无法还原一个病患的所有信息。
例如,节点A存储了佣兵的姓名和身高,节点B则存储了佣兵的过敏史,节点C则存储了我的手术史。但是,想要完整地获得我的健康信息,则没那么容易,你需要所有节点联合起来才能还原。因此,链下的存储一方面让每个节点存储的效率大大提升,另一方面则是让每个节点只能存储我的部分信息,却无法感知我的隐私情况。
就这样,隐私计算的概念进一步提升。
Enigma的网络确保正确执行代码,同时不会将原始数据泄露给任何计算节点。因为每个节点都确保存储了我的部分信息,因此只要让多方参与共同运算,我的信息就能被完整复原。这样的好处就是在于,当我们想要计算所有点的全部信息时,只要让每个节点利用本地数据计算出部分计算结果,然后最后让系统负责汇总即可。
这项计算,我们称为安全多方计算(sMPC或MPC)。
例如,我们还是讲回个人工资与整体平均的工资的例子,Enigma上每个节点都会存储部分人的工资数据。统计整个中国平均工资时,有个大管家叫做MPC,它一旦发动统计任务,她就会跑去各个节点获得统计人数和统计值,如节点A存储有500人,平均工资为5千元;节点B存储有100人,平均工资为1万元;节点C存储了1000人,平均工资为3000。那么MPC大管家则跑到每个节点处,问了结算结果后,中国的人均工资水平也就能计算出来。
这样的做法,其实在学术中已经有较多的研究放在这种隐私计算方式上,我比较熟悉的就是差分计算,从而能够完成的这样的计算。
总结
总的来说,通过以上的链上和链下数据治理方案,我们可以看到Enigma在数据隐私计算上既提升数据存储的隐私程度,也提高可区块链的可扩展性(即可以存储更多数据)。这两点需求是目前大规模数据落地区块链的可行方案。
并且随着Defi与物联网的崛起,区块链想要在金融行业和物联网行业快速发展,对于在区块链上发展的数据保护程度应该要进一步加深。例如,目前的Defi安全性全压在公链的智能合约上。一旦某个智能合约被黑客攻击,那后果将不堪设想。但如果将智能合约的数据存储在Enigma上,将进一步提升智能合约的安全度,减少不一样的风险。

此文为区分平台上的【精选评测】,如需转载请标明出处。
若项目方对评测内容有争议,请联系区分客服。